I’m a fan of simplifying as much as possible. One strategy I love to use is analogies.
I’m sure you’ve heard the phrase “it’s like riding a bicycle”. We all know what that means – once you’ve learned a skill, you can take a break from it, but regain it quickly if you start again later. Saying “it’s like riding a bicycle” encompasses not only this concept, but brings along a richness of emotion. Those summer days as a kid, riding your bike to the pool to meet up with some friends, maybe to grab an ice cream afterwards.
Managing teams is like stock market investing
Life at a fast-moving company is full of swings, highs, and lows. In software, there may be launches, bugs, or service outages that cause different individuals in the organization to go back and forth rapidly. In operations, there can be holiday sales, labor strikes, or equipment issues that cause huge variations in day-to-day work. This churn is often visible, through email escalations, phone alerts, or literal flashing red lights.
Managers often fail in one of their most important responsibilities: providing stability for their teams. As a manager, you are guiding your teams, helping them release products and triage issues. But, you’re not sitting side-by-side with every engineer, experiencing every bug fix with them. Your job is to smooth out bumps and valleys, and keep the team together as a unit. In times of crisis, you are there to calm them. In times of change, you are there to guide them through.
You are a smoothing function, like a moving average in a stock market graph.

The amount of smoothing you do is dependent on your role. As a front-line manager (the red trend line), you need to respond to day-to-day events that impact your team. But as a more senior manager, you should not respond too quickly. Overreacting to daily events leads to “knee-jerk reactions” or “seagull management“.
As you move into more senior management roles, you take on a broader perspective, and a longer-term view. Rather than managing one team and thinking daily or weekly, you are managing multiple teams and thinking monthly or quarterly (the green trend line). At the executive level, you are looking out 6-12 months and creating multi-year plans (the blue trend line). Your job is to provide a stable vision for the team, a North Star to navigate towards. In stock market terms, you are a daily, then a 50-day, then a 200-day moving average for your team.
Keeping in Sync
The stock market moving average analogy can be taken further. You’ll notice in the graph I chose that each of the management layers is somewhat out-of-sync. It gets particularly pronounced in the middle section, where lines cross and move in opposite directions. In our analogy, this could represent a change in strategy, or an internal reorganization. Eventually, leadership realigns, and the team can move forward.
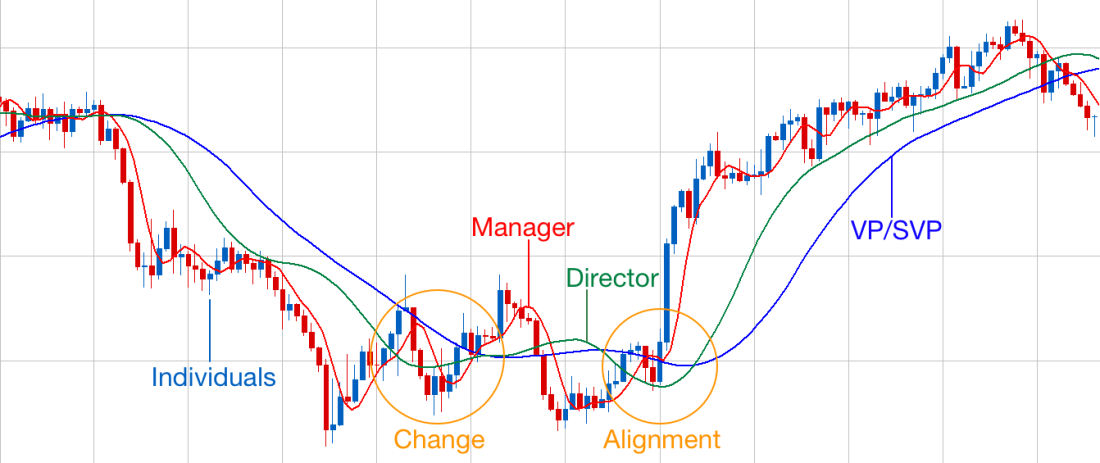
Notice that while leadership is not aligned, the team vacillates back and forth. When teams report feeling “churn”, this is what they are feeling.
The longer time period a moving average reflects, the more it can be out-of-sync with daily events. In the above graph, the Director and VP/SVP levels are stable on the down and up swings. But their version of reality is not entirely in sync with what is happening day-to-day. This is a common challenge for senior leadership.
This is where empowerment comes in. I would argue the above graph is healthy, if the front-line manager (the red trend line) is empowered appropriately. The long-term trend lines focus on the long-term, and the short-term trend lines focus on the short-term.
Having spent almost 7 years at Amazon, this is what Amazon does really well. Every “two-pizza team” owns their own destiny – the tools they use, the coding methods they follow, the internal systems they reuse (or don’t), the scrum discipline they adopt, and so forth.
I witnessed numerous Amazon new hires experience extreme culture shock. Over the years I heard people comment that it seemed like “general anarchy”, “barely controlled chaos”, or even simply, “I can’t believe a company can operate this way”. But consider the reverse. Think if every little decision about every feature, or toolset, or architecture choice had to go up to the VP layer (the blue trend line). The entire company would grind to a halt. Instead, it’s a rocket ship.
Try This
First, figure out what smoothing line you are supposed to be. Are you a front-line manager? Director? SVP? Make sure you are acting appropriately.
Second, are you empowering your people? Empowerment is a big one that pays off. If you challenge people with a stretch goal and tell them “I believe in you”, they can do amazing things. (Shocking, I know.)
Finally, if you have any great stock tips, let me know.



 What th
What th The consensus is that
The consensus is that 

 In my
In my  Sooner or later, your slick, smooth-running atomic system is going to have problems. Even if it’s well-engineered, you could have a large outage such as a system crash, datacenter failure, etc. Plan on it.
Sooner or later, your slick, smooth-running atomic system is going to have problems. Even if it’s well-engineered, you could have a large outage such as a system crash, datacenter failure, etc. Plan on it.